
2020.03.28
Organizational maturity and digital transformation
Brick-and-mortar, Fortune 2000 corporations undertaking “digital transformations” face a common problem: Where to start? I will get to that in a moment but first, semantics.
Different corporations mean different things by digital transformation. Yet, when all is said and done, we can boil it down to a two step iterative process, as outlined below:
The Digital Transformation Redux
- Increase direct sales through digital channels; and
- Enable a “flywheel effect”,
where the flywheel effect involves combining digital data, other data, and “artificial intelligence” to provide customers with “what they want, when they want it”.
The hope is that smart, personalized recommendations will beget more customers, more data, better algorithms, better personalized recommendations, and so on. The net, according to every consultant PowerPoint deck on the planet, is an inexorable march towards world domination. Caveat emptor.
Defined in this way, the answer to the question “Where to start?” appears obvious: “Data! Start with the data!”. After all, data are key to the whole strategy.
If only things were so simple.
There are two fundamental problems with the data first strategy.
First, traditional brick and mortar businesses were never set up to operate a flywheel. As a result, when you go looking for data what you find is not a pristine data lake, so much as a swamp full of scary zombies.
Second, if you do decide to make it your business to “clean the swamp”, then be forewarned. You are about to commit your entire organization – and career – to a multi-year lift, with highly uncertain returns.
The fact is, brick-and-mortar Fortune 2000 corporations lack the organizational maturity to undertake massive digital transformations. The reasons are multiple. Monica Rogati provides a great overview in her excellent post “The AI Hierarchy of Needs”.
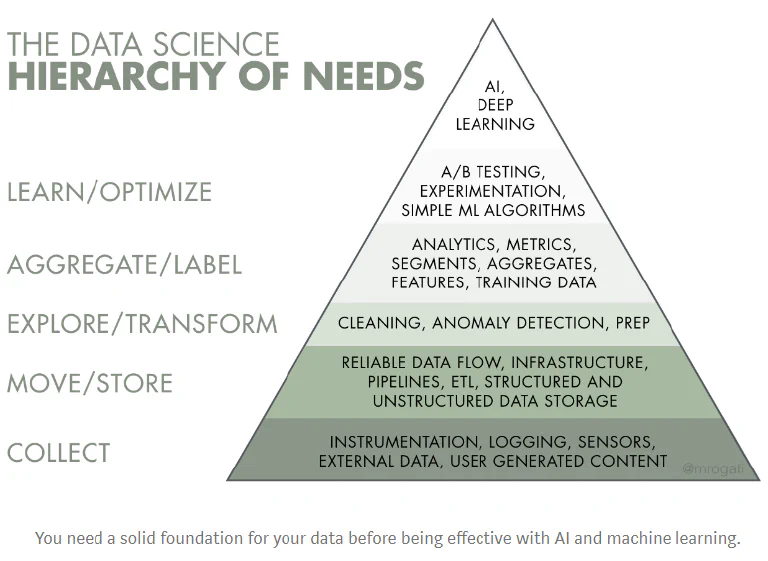 Source: Monica Rogati (@mrogati)
Source: Monica Rogati (@mrogati)
In Rogati’s view data are critical. However, she hits the nail on the head when she states:
The data science hierarchy of needs is not an excuse to build disconnected, over-engineered infrastructure for a year
Instead, we should identify end-to-end applications with high ROI, and few impediments, that can be implemented quickly. The aim is to build out the digital transformation one valuable vertical slice of the hierarchy-of-needs pyramid at a time. Doing so maximizes learning, and minimizes risk. Put differently, the way to cut an elephant is one elephant carpaccio slice at a time. (This is very much in line with standard agile practices of incremental development.)
Viewed in this way, a more sensible recommendation is to work backwards from business decisions.
For example, you might map out what are the most valuable decisions, then pick out those which may benefit the most from automation (e.g. personalized product recommendations), or additional information (e.g. forecasts). Finally, you can use any fancy framework to rank decisions, and prioritize the work.
Yet once again the lack of maturity comes to bite.
Meet the unknown unknowns. In my experience, the most binding constraint to any such prioritization is unstable, siloed data. For example, a database created by marketing for their own internal consumption, with a time varying schema, that is shared across the org as Excel email attachments. You get the idea.
(Side note: If you are an entrepreneur building automated machine learning solutions for Fortune 500 companies, now is the time to consider how long it is going to be, before your prospective customers are ready to adopt your product beyond pilot stage.)
Where, then, can we find valuable end-to-end slices, with high ROI, that can deliver value quickly, without fear of the unknown?
To answer this questions I recommend the following fast and frugal tree as the decision heuristic. Schematically, it goes like this:
- Does the organization rely mostly on its own generated data?
- If yes then will the organization be the primary consumer of the analytics output?
- If yes, then start here by working backwards from the most important decisions in this org.
- If not, then move on to the next org under consideration.
- If not, then move on to the next org under consideration.
The above can be represented in a two by two table, where you can lay out the various organizations within the corporation. Below is one such table for a fictitious example. Ruling out everything on the bottom row, and in the right column, leaves us with the digital organization.
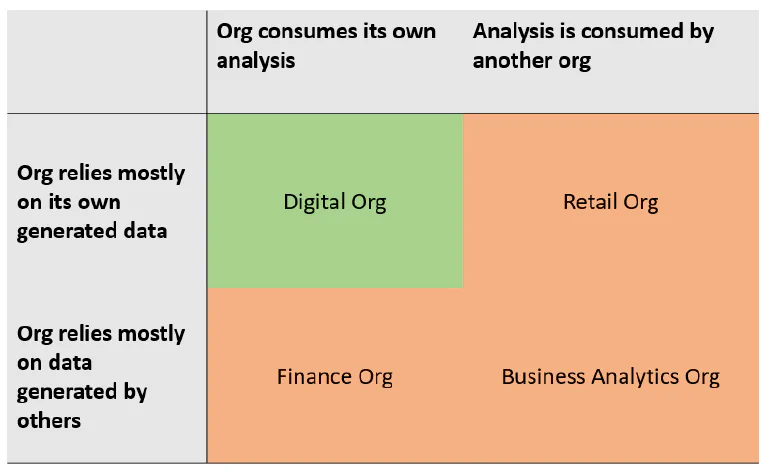 2 by 2 representation of the fast and frugal tree outcomes
2 by 2 representation of the fast and frugal tree outcomes
This makes sense. The digital organization is probably the most mature, from a digital transformation perspective, within any traditional brick-and-mortar company. Their tagging may not be up to par, and their websites slow and buggy but at least they own the entire operation, warts and all.
And therein lies the key. Machine learning (ML) systems are complex systems (PDF). For ML systems to have a fighting chance of working well at scale, they need a stable environment. On both the input side (i.e. the data), and the output side (i.e. decisions). Everything in between happens in silico. That is, it is deterministic (hardware withstanding), and so under control (more or less).
One critique of the above framework is my taking of the siloed swamp as given. Surely we can build APIs to overcome them. The risk here is adopting an “API first” strategy, with all the attendant risks of “cleaning the swamp”. Don’t get me wrong, APIs are needed. It’s just that they are even more awesome in the context of an end to end vertical slice with few unknown unknowns.
Another critique is that by pursuing the above heuristic we will build a “digitally transformed” silo. That is certainly a risk. Presumably, it is also an easy one to remedy through judicious org design (e.g. moving to a hub and spokes model), personnel rotations, and so on. The idea is to land, then expand.
Finally, it might be that after going through the heuristic, the top left cell in the table is empty. Namely, no org in the company is mature enough to begin building the vertical slices of your digital transformation. One possibility here is to prune the fast and frugal tree to just one cue (the rows). Another, is to focus on graduating some org to the top left cell.
Enjoyed this post? Subscribe via RSS to get new articles delivered to your feed reader.